MCMC Fitting
Another fitting method available in CRModel.fit() is Markov Chain Monte Carlo (MCMC). For the least-squares approach, see Least-Squares Fitting.
The CRModel.fit_mcmc() method performs Bayesian parameter estimation using MCMC sampling via the pymcmcstat library.
Background
To quantify uncertainty in the fitted parameters, we sample from the posterior distribution. As in Least-Squares Fitting, the difference between model predictions and observations is measured by the sum of squared scaled errors (SSE),
where \(\theta\) denotes the vector of model parameters, \(t_k\) are the measurement times, \(X_i(t_k)\) and \(S_j(t_k)\) are the observed concentrations, \(\hat{X}_i(t_k;\theta)\) and \(\hat{S}_j(t_k;\theta)\) are the corresponding model predictions, and \(s_{X,i}\) and \(s_{S,j}\) are scaling factors for species and metabolite residuals, respectively.
The sampler combines this likelihood with weakly informative priors on the parameters to generate posterior samples, and an initial burn-in period is discarded before analysis.
Example
We load experimental time-series data from the BT_WC_export.csv file and fit a consumer-resource model (CRM) to the data.
from mgrowthctrl.utils.data import Dataloader
from mgrowthctrl.models.crm.model import CRModel
data = Dataloader()
data.load_local_data(
"examples/datasets/BT_WC_export.csv",
x_selector=r"BT counts",
)
model = CRModel.from_single_species_data(
df=data.df,
time_col=data.time_col,
x_col=data.X_names[0],
s_cols=data.S_names,
)
We then fit the model with least squares to obtain a good initial parameter set.
model.fit(
df=data.df,
time_col=data.time_col,
x_cols=data.X_names,
s_cols=data.S_names,
)
Next, we use that fit as a starting point for MCMC sampling to quantify uncertainty.
result_mcmc = model.fit_mcmc(
nsimu=10_000,
sigma2=12.0,
burn=0.8,
seed=1234,
)
mcmc_sims = result_mcmc["mcmc_sims"]
sschain = result_mcmc["sschain"]
post = result_mcmc["post"]
param_names = result_mcmc["param_names"]
Finally, we visualize the MCMC error evolution, parameter distributions, and model trajectories.
from mgrowthctrl.utils.plot import (
plot_data_with_overlay,
plot_mcmc_error_evolution,
plot_parameter_distributions,
)
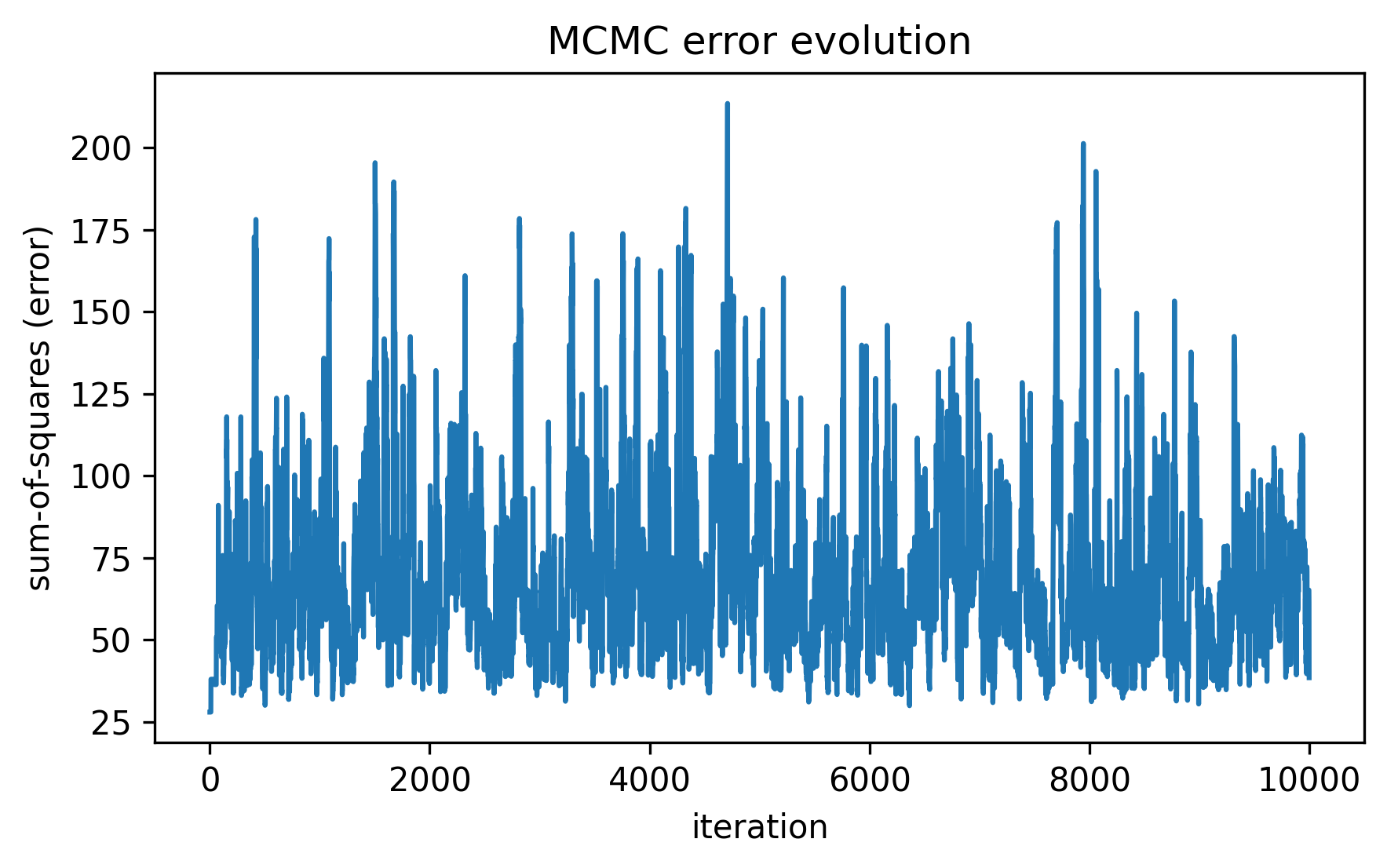
plot_mcmc_error_evolution(sschain, save_prefix="mcmc_error")
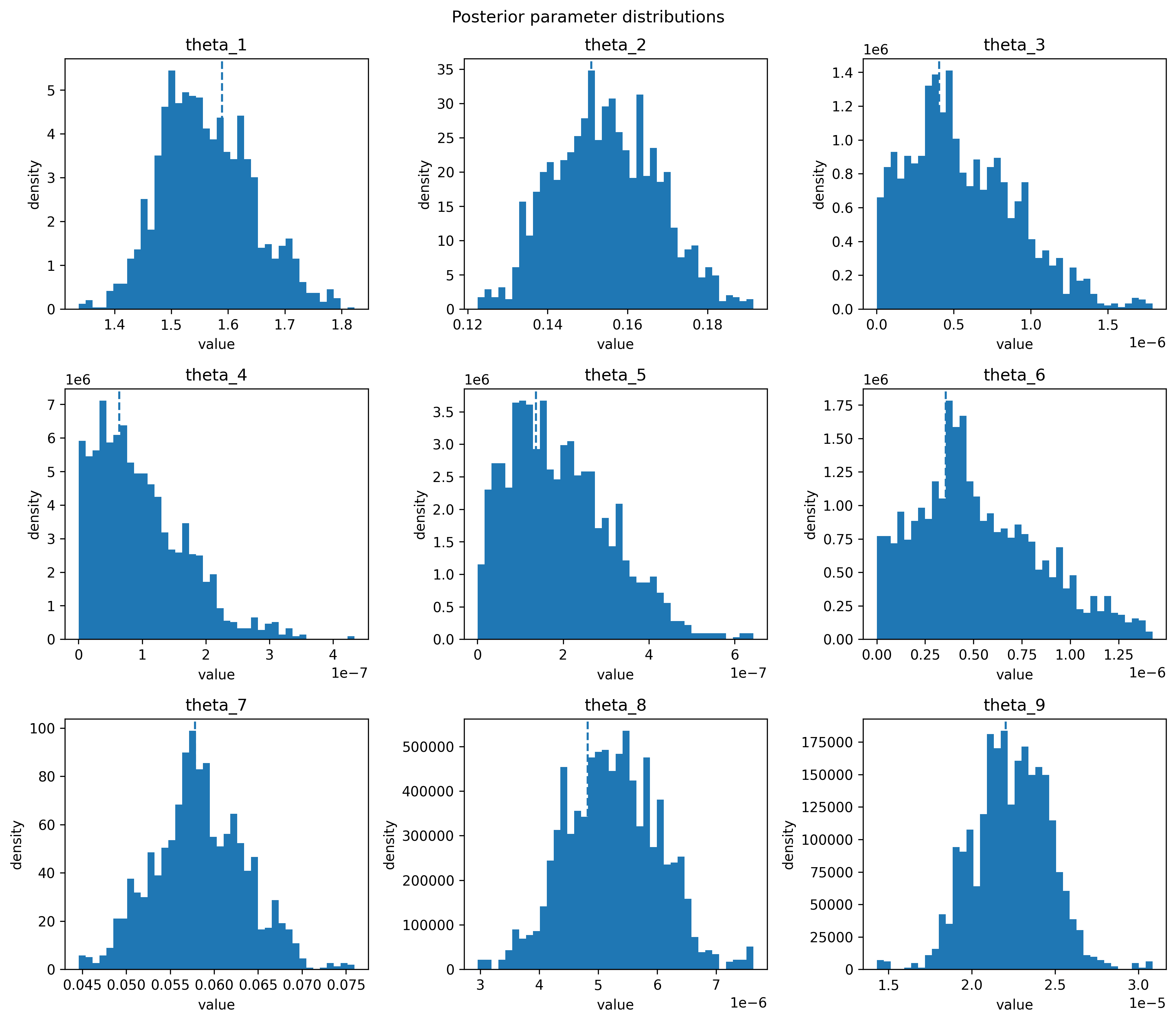
plot_parameter_distributions(
post,
theta_mle=model.theta_opt_,
names=param_names,
save_prefix="param_dist",
)
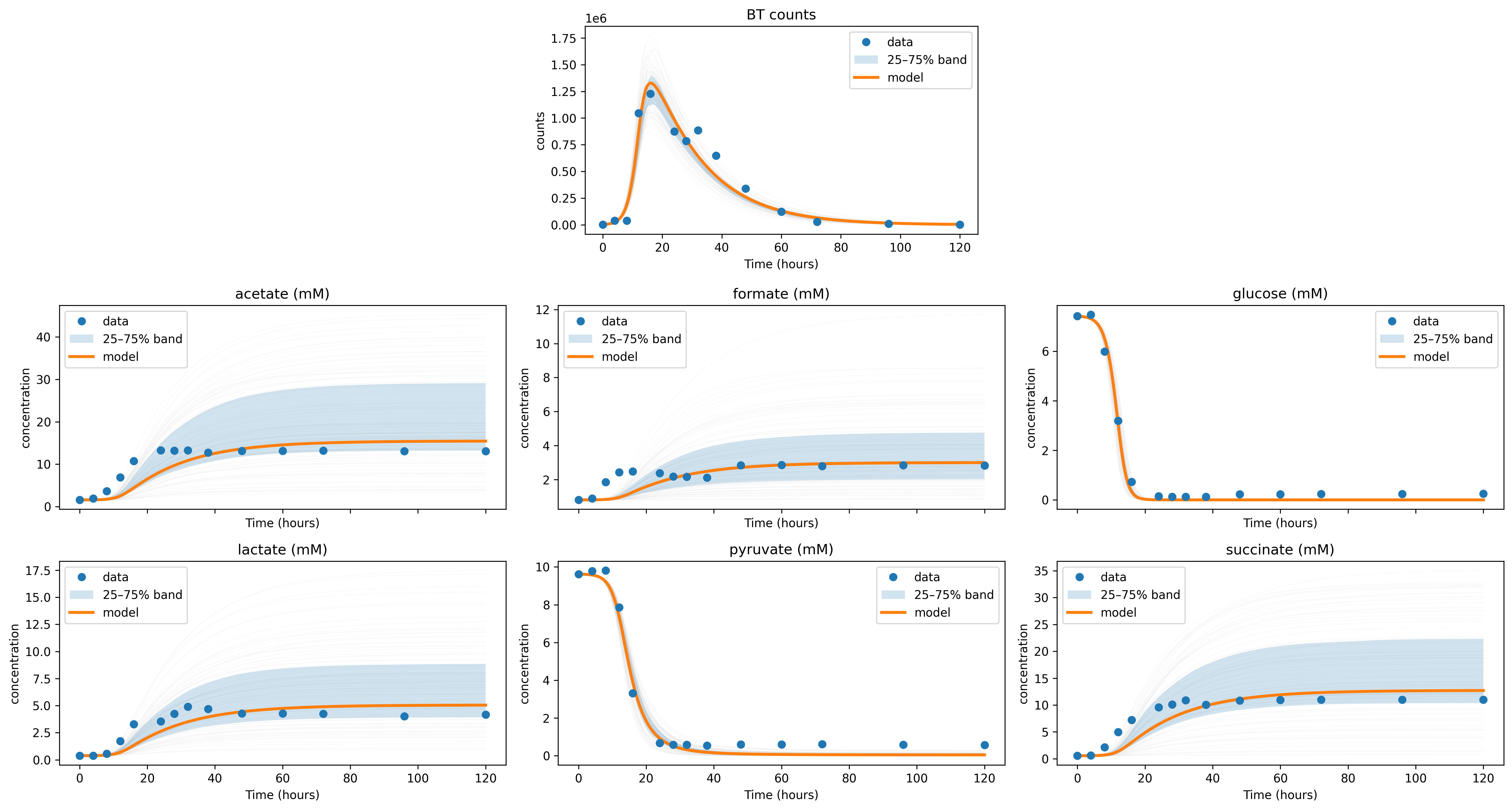
plot_data_with_overlay(
df=data.df,
sim=model.sim_opt_,
overlay="model",
time_col=data.time_col,
x_cols=data.X_names,
s_cols=data.S_names,
mcmc_sims=mcmc_sims,
thin_alpha=0.1,
thin_lw=0.5,
thick_lw=2.5,
shade_percentiles=True,
percentiles=(25, 75),
save_prefix="final_mcmc_fit",
)
The MCMC error evolution should look similar to the following example:
The parameter distributions should look similar to the following example:
The fitted model trajectories should look similar to the following example:
Backend API
- mgrowthctrl.models.crm.fit.crm_fit_mcmc(
- ctx: FitContext,
- theta0: ndarray,
- nsimu: int = 10000,
- sigma2: float = 12.0,
- burn: float = 0.8,
- nsamp: int = 200,
- seed: int = 1234,
Run MCMC around a given FitContext/theta0. See the documentation of the pymcmcstat package for more details.
Parameters: :param theta0: Initial values :param nsimu: Number of simulations in each chain :param sigma2: Initial observation error :param burn: Fraction of samples to drop as burn-in :param nsamp: Number of posterior samples to pick :param seed: Random seed
- Returns:
post, chain, sschain, param_names, picks, mcmc_sims
- Return type:
dict containing
- mgrowthctrl.models.crm.fit.crm_fit_mcmc_from_df(
- df,
- time_col: str,
- x_cols: List[str],
- s_cols: List[str],
- simulate_fn: Callable[[Dict[str, ndarray], ndarray, ndarray, ndarray], Dict[str, ndarray]],
- params0: Dict[str, ndarray] | None = None,
- *,
- lb_factor: float = 0.0,
- ub_factor: float = 10.0,
- X0: ndarray | None = None,
- S0: ndarray | None = None,
- include_metabolites: bool = True,
- weight: str = 'median',
- n_time: int = 300,
- fit_a: bool = False,
- nsimu: int = 10000,
- sigma2: float = 12.0,
- burn: float = 0.8,
- nsamp: int = 200,
- seed: int = 1234,
High-level MCMC fit for CRM parameters starting from params0.
Mirrors crm_fit_mechanistic, but runs MCMC and returns (ctx, result_dict).